The Problem
Given a cluster of RabbitMQ nodes, we want to achieve effective load-balancing.
The Solution
First, let’s look at the feature at the core of RabbitMQ – the Queue itself.
RabbitMQ Queues are singular structures that do not exist on more than one Node. Let’s say that you have a load-balanced, HA (Highly Available) RabbitMQ cluster as follows:
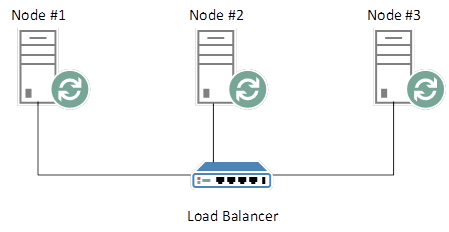
RabbitMQ Cluster with Load Balancer
Nodes 1 – 3 are replicated across each other, so that snapshots of all HA-compliant Queues are synchronised across each node. Suppose that we log onto the RabbitMQ Admin Console and create a new HA-configured Queue. Our Load Balancer is configured in a Round Robin manner, and in this instance, we are directed to Node #2, for argument’s sake. Our new Queue is created on Node #2. Note: it is possible to explicitly choose the node that you would like your Queue to reside on, but let’s ignore that for the purpose of this example.
Now our new Queue, “NewQueue”, exists on Node #2. Our HA policy kicks in, and the Queue is replicated across all nodes. We start adding messages to the Queue, and those messages are also replicated across each node. Essentially, a snapshot of the Queue is taken, and this snapshot is replicated across each node after a non-determinable period of time has elapsed (it actually occurs as an asynchronous background task, when the Queue’s state changes).
We may look at this from an intuitive perspective and conclude that each node now contains an instance of our new Queue. Thus, when we connect to RabbitMQ, targeting “NewQueue”, and are directed to an appropriate node by our Load Balancer, we might assume that we are connected to the instance of “NewQueue” residing on that node. This is not the case.
I mentioned that a RabbitMQ Queue is a singular structure. It exists only on the node that it was created, regardless of HA policy. A Queue is always its own master, and consists of 0…N slaves. Based on the above example, “NewQueue” on Node #2 is the Master-Queue, because this is the node on which the Queue was created. It contains 2 Slave-Queues – it’s counterparts on nodes #1 and #3. Let’s assume that Node #2 dies, for whatever reason; let’s say that the entire server is down. Here’s what will happen to “NewQueue”.
- Node #2 does not return a heartbeat, and is considered de-clustered
- The “NewQueue” master Queue is no longer available (it died with Node #2)
- RabbitMQ promotes the “NewQueue” slave instance on either Node #1 or #3 to master
This is standard HA behaviour in RabbitMQ. Let’s look at the default scenario now, where all 3 nodes are alive and well, and the “NewQueue” instance on Node #2 is still master.
- We connect to RabbitMQ, targeting “NewQueue”
- Our Load Balancer determines an appropriate Node, based on round robin
- We are directed to an appropriate node (let’s say, Node #3)
- RabbitMQ determines that the “NewQueue” master node is on Node #2
- RabbitMQ redirects us to Node #2
- We are successfully connected to the master instance of “NewQueue”
Despite the fact that our Queues are replicated across each HA node, there is only one available instance of each Queue, and it resides on the node on which it was created, or in the case of failure, the instance that is promoted to master. RabbitMQ is conveniently routing us to that node in this case:

RabbitMQ Cluster Exhibiting Extra Network-hop
Unfortunately for us, this means that we suffer an extra, unnecessary network hop in order to reach our intended Queue. This may not seem a major issue, but consider that in the above example, with 3 nodes and an evenly-balanced Load Balancer, we are going to incur that extra network hop on approximately 66% of requests. Only one in every three requests (assuming that in any grouping of three unique requests we are directed to a different node) will result in our request being directed to the correct node.
“Does this mean that we can’t implement round robin load-balancing?”
“No, but if we do, it will result in a less than optimal solution.”
“So, what’s the alternative?”
Well, in order to ensure that each request is routed to the correct node, we have two choices:
- Explicitly connect to the node on which the target Queue resides
- Spread Queues evenly as possible across nodes
Both solutions immediately introduce problems. In the first instance, our client application must be aware of all nodes in our RabbitMQ cluster, and must also know where each master Queue resides. If a Node goes down, how will our application know? Not to mention that this design breaks the Single Responsibility principle, and increases the level of coupling in the application.
The second solution offers a design in which our Queues are not linked to single nodes. Based on our “NewQueue” example, we would not simply instantiate a new Queue on a single node. Instead, in a 3-node scenario, we might instantiate 3 Queues; “NewQueue1”, “NewQueue2” and “NewQueue3”, where each Queue is instantiated on a separate node.
The second solution offers a design in which our Queues are not linked to single Nodes. Based on our “NewQueue” example, we would not simply instantiate a new Queue on a single Node. Instead, in a 3-node scenario, we might instantiate 3 Queues; “NewQueue1”, “NewQueue2” and “NewQueue3”, where each Queue is instantiated on a separate Node:

RabbitMQ Cluster with Separate Queues
Our client application can now implement, for example, a simple randomising function that selects one of the above Queues and explicitly connects to it. In a web-based application, given 3 separate HTTP requests, each request would target one of the above Queues, and no Queue would feature more than once across all 3 requests. Now we’ve achieved a reasonable balance of load across our cluster, without the use of a traditional Load Balancer.
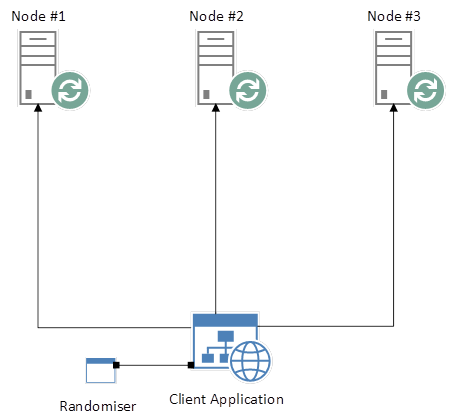
RabbitMQ Cluster with Randomiser
But we’re still faced with the same problem; our client application needs to know where our Queues reside. So let’s look at advancing the solution further, so that we can avoid this shortcoming.
Firstly, we need to provide mapping metadata that describes our RabbitMQ infrastructure. Specifically, where Queues reside. This should be a resilient data-source such as a database or cache, as opposed to something like a flat file, because multiple sources (2, at least) may access this data concurrently.
Now introduce an always-on service that polls RabbitMQ, determining whether or not nodes are alive. New Queues should also be registered with this service, and it should keep an up-to-date registry, providing metadata about Nodes and their Queues:

RabbitMQ Cluster with Monitor Service
Our client application, on initial load, should poll this service and retrieve RabbitMQ metadata, which should then be retained for incoming requests. Should a request fail due to the fact that a Node becomes compromised, the client application can poll the Queue Metadata Store, return up-to-date RabbitMQ metadata, and re-route the message to a working Node.
This approach is a design that I’ve had some success with. From a conceptual point-of-view, it forms a small section of an overall Microservice Architecture, which I’ll talk about in a future post.
Connect with me:

I’m setting up a rabbitmq cluster as well. With HA, the disk space for the cluster is no longer elastic. Any queues are replicated across all nodes. Kafka allows user to specify a replication factor. I think RabbitMQ should allow the same. I have yet to find anything like that for RabbitMQ.
Telling Ops to spin some vm instances and add to the cluster is a lot easier than tell them to add disk space to all the nodes in the cluster.
Thanks for your comment. No, there is no replication factor at the time of writing. Data is replicated across all mirrored nodes. It’s essential to implement extensive load-testing on any HA, distributed systems in order to ascertain the optimal amount of processing power, volatile and non-volatile memory necessary. As you said, upgrading HDDs is not an effective approach. Stress-testing should reveal the optimal configuration per node, and allow your Ops team to scale out as required, rather than scale up.
It doesn’t seem as though RabbitMQ is telling the client where its queue lies. How can this be?
Thanks for your comment, Charles. The Queue, when created, resides on the Node that the client either chose directly, or was routed to by a Load Balancer, for example. The Queue is essentially a Master Queue, with 0…* slaves. If a client needs to connect directly to that Queue, then it is the client’s responsibility to remember the Node on which the Queue resides.
If the client does not maintain, or refer to an index that maps Queues to Nodes, and instead relies on a Load Balancer that routes requests to the Node Cluster, then RabbitMQ will automatically route requests to the correct Node, if the request is routed to a Node that does not contain the desired Queue.
Hi, I can’t find any article explaining how to explicitly choose the node where you want the queue to be stored. Is this a part of the argument you can set when you declare the queue from the client API? Can you give some pointers to such documentation? Thanks!
Hi Jason, each node will either be a separate host, or will reside on the same host as all other nodes, but with a different port number. Specify the “Host” and “Port” properties pertaining to the desired node, in the Connection object, in order to connect to a specific node.
Hi Paul,
Just a question, if I’ve understood correctly your application chooses one of the 3 queues to use it, but what about other apps that need to grab information stored in NewQueue[1-3], will it have to take a look at all of them to grab the content?
Thanks,
David
Hi David, thanks for your comment. Are you referring to downstream applications that listen to the Queues? If so, based on my example of NewQueue[1-3], I would initialise at least 1 listener application for each Queue. Essentially every unique Queue will require 1…n downstream listeners.
Would it be possible for the TCP load balancer to check RabbitMQ via an HTTP endpoint to see which is master? If there was a way to determine which is master over an HTTP call for example, the load balancer could only route to that node and see all other nodes as “down” for the health check (though in this case down equates to not master). Then when the master flips the load balancer could as well… but this all hinges on being able to tell which is master from outside the Rabbit internal processes.
Hi Kyle, thanks for your comment. Yes, you can leverage the HTTP API in order to return a JSON response that details the list of available Queues. The Master Queue in this response should be marked with a “node” property.
You could potentially poll the HTTP API to keep track of this, and modify your Load Balancer configuration appropriately, in the event of node-failure.
If master and slaves are really having reliable connection where network partitioning happening very rarely, can we configure in a way that rabbitmq allows to subscribe to any slave node queue to reduce the load to master queue, if not available in slave queue slave should sync with master queue and return it ?
No, if a client attempts to connect to a slave node, RabbitMQ will route the connection to the master node. Clients cannot leverage slave nodes unless the master node is removed and the slave promoted to master.
Thanks for such a great article! We are already trying to deal with HA.
Question: You say “No, if a client attempts to connect to a slave node, RabbitMQ will route the connection to the master node”. In case we have firewalls everywhere does that mean, that client should have to both master and secondary machine – it should be capable to open port 5672 of both machines? So this redirection means a command for client (on a driver level) – “Go and reconnect that machine”?
You’re welcome. Your client will need an accessible TCP connection to the active master node. It is highly advisable that your client also have accessible connections to all slave nodes, ensuring availability in the event of master-node failure.
Hi Paul,
First thing, very good article! I have a very basic question here. I was unable to verify whether the queue is “actually replicated” in the other node. How do we ensure that its “replicated”? Could you please throw some light on this?
Thank you. In any given cluster of at least 2 nodes, one node will function as master, the other(s) as slave(s). RabbitMQ automatically handles replication asynchronously – a worker task is initiated when messages arrive on, and are dispatched from the master Queue. This worker task replicates the action on the slave Queue(s).
You can confirm the existence of associated slave Queues by running an application against your cluster, and deactivating (forcing shutdown, etc.) the master node. After a failover period, the next applicable slave will be promoted to master, and normal service will resume, confirming the existence of replicated Queues.
It’s worth noting that if a node is lost while replication data is in-flight, that is, data that has not yet been committed to replicated Queues, that data will be lost. This is a corner-case, and applies to any distributed system.
Hi Paul,
What happens when there is a split brain situation (as in Distributed Computing) with master and slave (mirrored) nodes ? I have 2 rabitmq mirrored servers and a haproxy load balancer directing the requests amongst these two. I blocked the communication between the rabbitmq servers manipulating the iptable rules of one of the rabbitmq servers. Now there is no mirroring. Now both the servers think both of them are the masters. How does rabbitmq handle this situation ? Please explain.
This is a very unusual scenario. Firstly, your load balancer is Likely superfluous, given that RabbitMQ will automatically route requests to the node upon which the master queue resides, regardless of your HA Proxy configuration.
You don’t mention your mirroring policy. Please refer to this overview, which may help in determining the node upon which your master queue will reside as a result of mirroring – it may not end up on the node upon which it was created:
https://www.rabbitmq.com/ha.html#genesis
Disabling communication between RabbitMQ nodes will result in disruption of RabbitMQs fundamental operations. Your situation is quite unusual, but I imagine that, given the loss of communication between nodes, each node engages failover mode, assuming that it is the only available node, and therefore assumes master status. I will dive deeper into this and provide a more definitive explanation, if necessary.
What problem is your solution designed to address? Or, are you experimenting with RabbitMQ from an R&D perspective?
Let me know if I can be of any more help either way.
Hi Paul
How do you explicitly define where the queue must be created on which node?
Hi Jason, each node will either be a separate host, or will reside on the same host as all other nodes, but with a different port number. Specify the “Host” and “Port” properties pertaining to the desired node, in the Connection object, in order to connect to a specific node.
Hi Paul, thanks for the fast response. I think where I am confused is that I do not know which APIs from RabbitMQ to use to retrieve where the master node is that is hosting the queue in the cluster when binding and declaring the queue programmatically. Perhaps its trivial to find out this info? I just don’t see how I can do this from the RabbitMQ API or I misunderstood your article. Apologies for my oversight if this can be done and I’d appreciate if you can explain further when you have time.
Hi Jason, you have to store the Queue metadata – that is, the index associating each Queue to a specific Node, somewhere accessible by your client application. This concept is outlined in the final diagram in this tutorial, above, labelled “RabbitMQ Cluster with Monitor Service”. In the above case, the Queue metadata is stored offline, accessible by the client, in a small repository called “Queue Metadata Store”.
Hi Paul, how do we obtain the Queue metadata before storing it? I see you have a monitoring service but how does this monitoring service obtain the info on where RabbitMQ stores the exchange and queue at a specific node? Is this possible to do it from RabbitMQ client API or is this out of the scope of RabbitMQ API?
You must use the Management API to return Queue metadata:
http://stackoverflow.com/questions/24402399/curl-to-get-rabbitmq-queue-size
http://hg.rabbitmq.com/rabbitmq-management/raw-file/3646dee55e02/priv/www-api/help.html
It’s a RESTful API so you will need to parse the response appropriately.
Thanks for those helpful links Paul. Here are some thoughts..if the RabbitMQ team decides to update the Management plugin, the values read by the monitor might change a little (if it does ever change) so one must handle for such change at the monitor so that the Queue Metadata store is not affected. Another concern is obviously there should be more than one monitor so that there isn’t a single point of failure. Thanks for writing this up, makes people think! :).
No problem. Thanks for your suggestions. Yes, as with any interface, change must be accounted for in terms of the underlying contract. Running multiple monitors will require you to synchronise auto-scale messages to prevent the same service receiving messages from multiple monitor instances. Let me know if you need any more info.
In case of separating queues as shown on “RabbitMQ Cluster with Separate Queues”, how you can keep order of the messages?
Let’s say we have a queue with 3 messages and the order of consuming those 3 messages does matter, and we put each of those messages in 3 different queues. Then for consuming them in proper order we need some extra logic to decide about the order, so this way load balancing is not feasible, right?
The problem is that adding this “extra logic” would be a complicated logic and would require many changes.
Do you have any suggestion about handling this?
Thanks for your comment. Yes, indeed we will need to implement client-side logic in order to process each of the 3 messages in correct order. This is a common problem when, for example, implementing Microservices, given that RabbitMQ does not guarantee atomicity when publishing to multiple queues. I address the issue and offer a solution using a concept called queue-pooling in this post:
Let me know what you think.
Hi, Paul
What a remarkable article! It helps me understanding many questions which puzzled me for a long time.
I still have two questions: a. I have to build RabbitMQ cluster for every independent application in order to isolate with each other, which indeed is a waste of resource. Is it possible to use only one cluster to achieve it and meet the previous goal at the same time?
b. If there is a network partition happens, what is the client will be affected.
Hi Carl. Thanks for your comment. Yes, without knowing a great deal more about your solution I can’t think of any reason why a single cluster could net facilitate your design.
In a design sufficient to facilitate the concept of high availability, should a network partition occur, the failing node should be demoted from “master” status by the RabbitMQ cluster, and the next logical “slave” node, assuming availability, should be promoted to master in its place.
In terms of data loss, RabbitMQ synchronises nodes asynchronously whenever data is modified on the master node. Slave node(s) should receive synchronisation metadata at a point in time after the initial data load. Assuming that this has taken place prior to the network partition, your newly promoted slave node should by consistent. However, there is a chance that it will be inconsistent if the data synchronisation process was interrupted by the network partition.
Thank you! Your reply helps me a lot.
Recently, I met an issue about Rabbitmq. The cluster is under LVS; clients connect mq through vip of LVS. When I do the pressure test by writing messages to mq, client reports error log like the following:
java.net.SocketTimeoutException: connect timed out
at java.net.PlainSocketImpl.socketConnect(Native Method) ~[na:1.7.0_45]
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) ~[na:1.7.0_45]
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) ~[na:1.7.0_45]
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) ~[na:1.7.0_45]
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) ~[na:1.7.0_45]
at java.net.Socket.connect(Socket.java:579) ~[na:1.7.0_45]
at com.rabbitmq.client.impl.FrameHandlerFactory.create(FrameHandlerFactory.java:32) ~[amqp-client-3.3.0.jar:na]
at com.rabbitmq.client.ConnectionFactory.newConnection(ConnectionFactory.java:588) ~[amqp-client-3.3.0.jar:na]
at com.rabbitmq.client.ConnectionFactory.newConnection(ConnectionFactory.java:624) ~[amqp-client-3.3.0.jar:na]
However, If I change the client connect mq directly, pass by LVS, with the same write speed everything is goes fine. The LVS policy is Round Robin, not persistent. I also tried to modify it to SourceIP Hash and persistent for half an hour, but the error is still occurs.
Wish you can offer me some advices~
It looks like the TCP connection is being severed due to inactivity. RabbitMQ clients emit a heartbeat at default intervals of 60 seconds in the latest version, and 580 seconds in older versions. This can be problematic for Load Balancers which often require more frequent traffic in order to maintain connections. Try lowering your RabbitMQ client heartbeat to 5 – 10 seconds to satisfy your Load Balancer configuration. I recommend determining exactly your Load Balancer connection timeout and adjusting your RabbitMQ client heartbeat to suit.
Thank you for your support it helped me a lot, the port is closing eventually
Hmm… Very impressive!
I also have met a new issue nowadays. I configured the cluster HA, autoheal when detect network partition. But it does not work at all. The details is described here. http://stackoverflow.com/questions/33955423/rabbitmq-ha-cluster-autoheal-failure-after-network-partition
Wish you can guide me some hints.
By the way, the connection reset by Load Balancer should be happened when connection is idle. While at the moment, the message write speed near 300 per second. Maybe there are some other reasons
Is it possible that your Load Balancer is configured as a circuit breaker, to throttle inbound requests if the reach a certain number, killing the connection?
we have three node rabbitmq cluster with ha-all policy ,when one node is down it is successfully migrating ownership to one of the other nodes but when the node is up how to re balance the ownership of queues or how to get back the ownership of migrated queues to the old node in the cluster?
RabbitMQ will automatically promote each replicated Queue from the failed node to “master”. An asynchronous process has been synchronising the now failed node Queues with their master equivalents to achieve consistency. If you leverage a Queue Metadata Store, as per the example in this post, you will need to update its index to reflect the newly promoted Master Node by subscribing to client connectivity-failure events.
sorry i couldn’t get you exactly ,can you please elaborate
Let me see if I understand the problem:
1. You have a 3-node cluster
2. Node x is lost
3. Failover occurs
4. Node x is recovered
In this case, you would like the original state of the cluster to be restored. That is, Queues whose master instances resided on Node x should be reinstated to Node X. Is this correct?
If so, I don’t think that this can be achieved in any straightforward manner. RabbitMQ handles rebalancing automatically. You would have to delete the Queues that had been synchronised from Node x after failover, and manually create them on Node X, after it is brought back into rotation.
Thank you Paul i have been trying to achieve this by nodes policy but couldn’t be able to achieve this
You’re welcome. As I mentioned in the previous comment; you can’t achieve this through configuration, instead, you must implement a custom solution as per my example.
Where do we can find the source code for ownership migration of rabbitmq cluster??
I don’t have a example of that. My next series of posts are set until January. I’ll look at providing an example after these have been released.
I mean rabbitmq implementation code for that
Yes, I understand. This post is conceptual, outlining potential high-level design considerations for RabbitMQ clusters. The implementation is left up to the reader. As I mentioned, I may deliver a post in future that covers implementation details, such as your use case.
we are running a three node rabbitmq cluster with ha-all policy and with pause_minority mode.
case1:(when we have queues for which the node is master)
if we add a rule to block 25672 in the node, then it pause_minority works fine as node is bringing down the port 5672 inactive
case2:(when there are no queues for which it is the master only syncing queues are present)
adding ip rule to block 25672, then it is showing network partition and also port 5672 is active and listening(acting like an ignore case)
how to solve this issue? is there any change in configuration of rabbitmq?bug??
At this point I’ve offered as much effective help as I can without becoming directly involved in your project. I would need to replicate your infrastructure exactly in order to determine the problem, if any. The RabbitMQ team are in a better position to do this, and are better positioned to offer adequate time. I might direct you to them here: https://groups.google.com/forum/#!forum/rabbitmq-users
Please post here as your case progresses.
Hi Paul ,
Thank you for your article , it helps me a lot !
I am not sure if I understand rightly , so could you kindly give me some advise?
in the final solution, in a 3-node scenario, do we need to instantiate 3 Queues; “NewQueue1”, “NewQueue2” and “NewQueue3”, where each Queue is instantiated on a separate Node .we publish the message to each queue .using the monitor service to watch which is reachable and provide these to the client application .the client application randomly choose one of the reachable queue for consuming , is this your thought ?
Besides , if it is possible for you to share your thought of the monitor service ? which tool would you use to monitor it ?is it possible for you to share your code of the monitor service ? Thanks.
Hi Bin Wu,
Thanks for your comment. Yes, that’s it exactly. As regards the monitor service, RabbitMQ provides a Management API that can be queried in order to determine the existence and state of any node. I recommend polling this API at regular frequencies to maintain an active list of all nodes. More information on leveraging the Management API through a tool called QueueWatch here: https://insidethecpu.com/2015/09/11/microservices-in-c-part-5-autoscaling/
Hi Paul,
Thank you very much for your advise!!
hi Paul,
So as your thought , we didn’t need to use the official cluster solution , right?
Actually, I don’t advocate this solution as a drop-in replacement for clustering, however, if extremely efficient load-balancing is a requirement of your application, then this solution can be implemented as-is, or in conjunction with clustering.
hi, i have a topology filebeat -> logstash -> [rabbit cluster 2 node] -> lostash -> elastic search. how we can output logstash to 2 node rabbitmq without load balancer
Configuring Logstash to point at either RabbitMQ node should result in RabbitMQ automatically routing connections to the correct node, long as your cluster is configured. In order to achieve more efficient balance, this article covers custom applications, rather than 3rd party applications such as Logstash.
Thank you, but if i point at 1 node master, master node die, how rabbit can auto routing to slave node
In the event of master node death, the slave node will be promoted to master automatically in a highly-available scenario. Point Logstash at your RabbitMQ Broker (cluster) in order to achieve this. More info here: https://www.rabbitmq.com/clustering.html
I have a rabbitmq cluster composed of A and B nodes,and it doesn’t employ HA policy at all.There exists a queue named ‘HelloWorld’ which resides on A node.
I want to ask two questions:
1)A producer client publish messages to the ‘HelloWorld’ queue which has connected to node B,so what happens?Message is first transfered to node B from the producer,then transfered to node A? Or Message is straightly transfered to node A from the producer?
2)A consumer client consume message from the ‘HelloWorld’ queue which has connected to node B,so what happens?Message is first transfered to node B from node A,then transfered to the consumer? Or Message is straightly transfered to the consumer from node A?
Thanks very much!
You mention that the client is “connected to node B”. Does this imply that the client is explicitly connected to node B by IP or DNS? In this case, yes, the request will be routed from node B to node A, where the queue resides.
A consuming client that connects to node B will be routed to node A, where the queue resides. The message itself will be returned directly to the client – it will not return through node B on route to the client.
A small hack . RabbitMQ Cluster with Load Balancer [Haproxy]:
Lets say we know the master of rabbitmq cluster or a node which is master of most of the queues.
Then we can configure our haproxy such that master rmq is only node receiving traffic and other nodes will be configured as backup nodes. This backup nodes will receive the traffic only when this master dies.
In this case we can reduce the extra network hop from slave to master since all the request are going to master and we get the HA as well
That will work fine, long as you know which node is master.
Hi Paul,
Thank you for the article. I am assuming a TCP load balancer such as HAProxy cannot redirect clients to the correct queue master since it may not know the queue which the clients want to publish/consume from. So I am considering following topology for my RabbitMQ Cluster:
Nodes A, B and X in a cluster. Node A will be the Queue Master and B will the be the Slave. Node X will not mirror/host any queues, but will act as Load Balancer. All producer/consumer clients will connect to Node X, and Node X will know where to redirect the clients. I can scale the above cluster with additional queues and nodes, but Node X will always act as a LB.
The problem would arise if Node X goes down, but it would be similar to the scenario where HAProxy goes down.
I would greatly appreciate if you can let me know if there are any drawbacks to this approach.
It’s actually the RabbitMQ cluster manager that controls traffic flow. In this case, your Node X is redundant. RabbitMQ will control the flow and persist traffic to the appropriate node, regardless of whether Node X is present or not.
Nice post Paul. Thanks for sharing.
I believe, Apache Zookeeper can solve the issue of extra hop problem. All the consumer will connect to Zookeeper to determine which RabbitMQ node to connect for asked queue.
One application(Topology updater) sits in between the Zookeeper and RabbitMQ which will update the Zookeeper node (zkNode) about cluster topology which will help consumers as mentioned.
Sounds good, I would be interested in reading a post about that
Any documentation or articles on this type of setup?
Everything is on this blog. The code samples contain documentation per method and class.
Hey Paul, thanks for this useful post. However I have a concern. I have setup a 3 node RabbitMQ HA Cluster (Mirroring enabled) with an azure load balancer. My client application points to the cluster and connects to the queue master. However, when the Master dies, another slave is promoted as master but my client application connection breaks to the cluster. Is there any way the connection is transferred to the new Master? Thanks.
The connection will persist until explicitly closed, or in your case, broken. You need to catch the connection exception and retry. Assuming that the slave is promoted to master in time, normal service will resume.
Hi Paul,
I like using RabbitMQ to produce and consume message in Zookeeper in Java . I didn’t find any single sample project for that.
Could you help me to achieve that?
All code sample for this post are in C#, and should be reasonably straightforward to convert to Java. I’m happy to help you if you provide more info as regards what you’re trying to achieve.
Pingback: How To Build Rabbitmq C Client | Information
Can you explain followed behvaior of queues on Rabbit
I have Rabbit Cluster with 2 nodes.
I create Mirrored Queue + 1 Consumer in my application (i see queue with 1 consumer on Rabbit UI)
I kill (stop) master Rabbit MQ node and the see my queue with 2 consumers on slave.
Each restart (more correct stop) of master Rabbit node causes to creation and registration of additional consumer and as result – unacknowledged messages accumulation on the queue…
Thnaks! Peter
Yes, the consumer needs to connect to your new node; that is, the former slave node that has been promoted to master. In doing so, it must severe the previous connection and establish a connection to the new master node.
Great article sir…
Can you tell me that the concept of master and slave is only in Clustering right. What we can do for shoveling.. Like I have make shovel between my 2 Dedicated Servers, I am producing message on 1st server and I can consume it from any of the 2 servers.. but when i produce message on my 2nd server I can’t consume it from 1st server… how can I do that??
Can you provide more detail as regards your configuration, please? It is likely that the consumer on your first server is listening to the first server, as is the consumer on the second server.
There is another feature of RabbitMQ which can provide some better behavior when you want a client to have a single place to get data from. Federated Queues help manage data routing in a multi-source and multi-client environment where you really need to scale out processing loads in a more fan like mechanism.
https://www.rabbitmq.com/federated-queues.html
Really nice feature, thanks for the update!
Are all the messages between newqueue1,2 and 3 are synchronised?
Do you mean synchronised in terms of order?
Nice article , loved the way you explained . Just want to know , how if we use federated queues option , which is available now, will remove the network hopping or not ? As every queue is peer , and there is no leader/follower in federated queues.
Thank you very much. I haven’y worked on this in many years so I’m not sure how federated queues would affect the system, but I suspet, as you suggested, that it would reduce network-hopping.