
Scaling out our Microservices
So far, we have
- established a simple Microservice
- abstracted and sufficiently covered the Microservice core logic in terms of tests
- created a reusable Microservice template
- implemented the queue-pooling concept to ensure reliable message delivery
- run simple load tests to adequately size Queue resources
Now it’s time to scale out. Here’s how our design currently looks:

Our current design
This design is fine for demonstration purposes, but requires augmentation to facilitate production release. Consider that the current design will only service a single request at any given time, and will service requests in a FIFO manner, assuming that no hardware failure, or otherwise, occurs.
Even under ideal conditions, assuming that each request takes exactly 1 second to complete, given 100 inbound HTTP requests, the 1st request will complete in 1 second. The final, 100th request, will complete in 100 seconds.
Clearly, this is less than ideal. Intuitively, we might consider optimising the processing speed of our Microservice. Certainly this will help, but does little to solve the problem. Let’s say that our engineers work tirelessly to cut response times in half:

Working tirelessly to shatter response-times!
Even if they achieve this, in a batch of 100 requests, the 100th request will still take 50 seconds to complete. Instead, let’s focus on serving multiple requests in a concurrent, and potentially parallel manner. Our augmented design will be as follows:

Augmented design
Notice that instead of a single instance of SimpleMathMicroservice, there are now multiple instances running. How many instances do we need? That depends on 2 factors – response times and something called Quality-of-Service (QOS).
Quality of Service
Quality of Service is a feature of AMQP that defines the level of service exhibited by AMQP Channels at any given time. QOS is expressed as a percentage; 100% suggests that any given channel is utilised to maximum effect. Essentially, we need to avoid downtime in terms of channel-usage. Downtime can be described as the period of time that a Microservice is idle, or not doing work.
Typically, such scenarios occur when a Microservice is waiting on messages in transit, or is itself transmitting message-receipt acknowledgements to the Message Bus. For more information on QOS, please refer to this post. For the moment, we’re going to begin with the most intuitive design possible, without delving deeply into the complexities of QOS, and related concepts such as prefetch-count.
To that end, we are going to deploy multiple instances of our SimpleMathMicroservice (10, to be exact), and retain the default message-delivery mechanism – to read each message from a Queue one-at-a-time. In order to achieve this, we must modify our application slightly, specifically, the Global.asax.cs file. First, add a simple collection to house multiple running SimpleMathMicroservice instances:
private readonly List<SimpleMathMicroservice> _simpleMathMicroservices = new List<SimpleMathMicroservice>();
Now, instantiate 10 unique instances of SimpleMathMicroservice, initialise each instance, and add it to the collection:
for (var i = 0; i < 10; i++) {
var simpleMathMicroservice = new SimpleMathMicroservice();
_simpleMathMicroservices.Add(simpleMathMicroservice);
simpleMathMicroservice.Init();
}
Finally, modify the Application_End function such that it gracefully shuts down each SimpleMathMicroservice instance:
foreach (var simpleMathMicroservice in _simpleMathMicroservices) {
simpleMathMicroservice.Shutdown();
}
Now, on startup, 10 instances of SimpleMathMicroservice will be invoked, and will each actively listen to the Math Queue.
Message Distribution
SimpleMathMicroservice leverages a component called AMQPConsumer within the Daishi.AMQP library that defines the manner in which SimpleMathMicroservice will read messages from any given Queue. AMQPConsumer exposes a constructor that accepts a value called prefetchCount:
protected AMQPConsumer(string queueName, int timeout, ushort prefetchCount = 1, bool noAck = false,
bool createQueue = true, bool implicitAck = true, IDictionary<string, object> queueArgs = null) {
this.queueName = queueName;
this.prefetchCount = prefetchCount;
this.noAck = noAck;
this.createQueue = createQueue;
this.timeout = timeout;
this.implicitAck = implicitAck;
this.queueArgs = queueArgs;
}
Notice the default prefetchCount value of 1. This default setting results behaviour that allows the component to read messages one-at-a-time. It also ensures that RabbitMQ will distribute messages evenly, in a round-robin manner, among consumers. Now our application is configured to process multiple requests in a concurrent manner.
Concurrency and Parallelism
Can our application now be described a parallel? That depends. Concurrency is essentially the act of performing multiple tasks on a single CPU, or core. Parallelism on the other hand, can be described as the act of performing multiple tasks, or multiple stages of a single task, across multiple cores.
By this definition, or application certainly operates in a concurrent manner. But does it also operate in a parallel manner? That depends. Running the application on a single core machine obviously prohibits parallelism. Running on multiple cores will very likely result in parallel processing. Under the hood, the Daishi.AMQP library invokes a new thread for each Microservice operation that consumes messages from a Queue:
public void ConsumeAsync(AMQPConsumer consumer) {
if (!IsConnected) Connect();
var thread = new Thread(o => consumer.Start(this));
thread.Start();
while (!thread.IsAlive)
Thread.Sleep(1);
}
“Wait, you shouldn’t invoke threads manually! That’s what ThreadPool.QueueUserWorkItem() is for!”
ThreadPool.QueueUserWorkItem() invokes threads as background operations. We require foreground threads, to ensure that the OS provides enough resources to run sufficiently, and also to prevent the OS from pre-empting the thread altogether, in cases when heavy load reduces resource availability.
Assuming that batches of newly created threads run (or are context-switched) across multiple cores, one could argue that our application exhibits parallel processing behaviour.
Run an ApacheBench load test against the running application:
ab -n 10000 -c 10 http://localhost:46653/api/math/1500
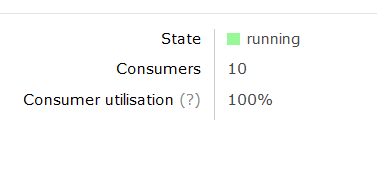
While the test is running, refer to the Math Queue in the RabbitMQ Administrator interface:
http://localhost:15672/#/queues/%2F/Math
Notice the number of Consumers (10) and the Consumer Utilisation figure. This figure represents the QOS value associated with the Queue. It should settle at the 100% mark for the duration of the test, indicating that each of all 10 SimpleMathMicroservice instances are constantly busy, and not idle:
Quality of Service
Next Steps
Modify the number of running SimpleMathMicroservice instances, and apply load tests to each setting. Ideally, push the number of running instances upwards in reasonable increments (batches of 5-10) and observe the response times, comparing each run against the last.
Response times should improve incrementally, then plateau, and ultimately decrease as you increase the number of running instances. This is an indication that your application has reach critical mass, based on the law of diminishing returns. Doing this will yield the number of SimpleMathMicroservice instances that you should deploy in order to achieve optimal throughput.
Connect with me:



