Microservices in Action
Microservices with C# and RabbitMQ
Overview
Microservices are groupings of lightweight services, interconnected, although independent of each other, without direct coupling or dependency.
Microservices allow flexibility in terms of infrastructure; application traffic is routed to collections of services that may be distributed across CPU, disk, machine and network as opposed to a single monolithic platform designed to manage all traffic.
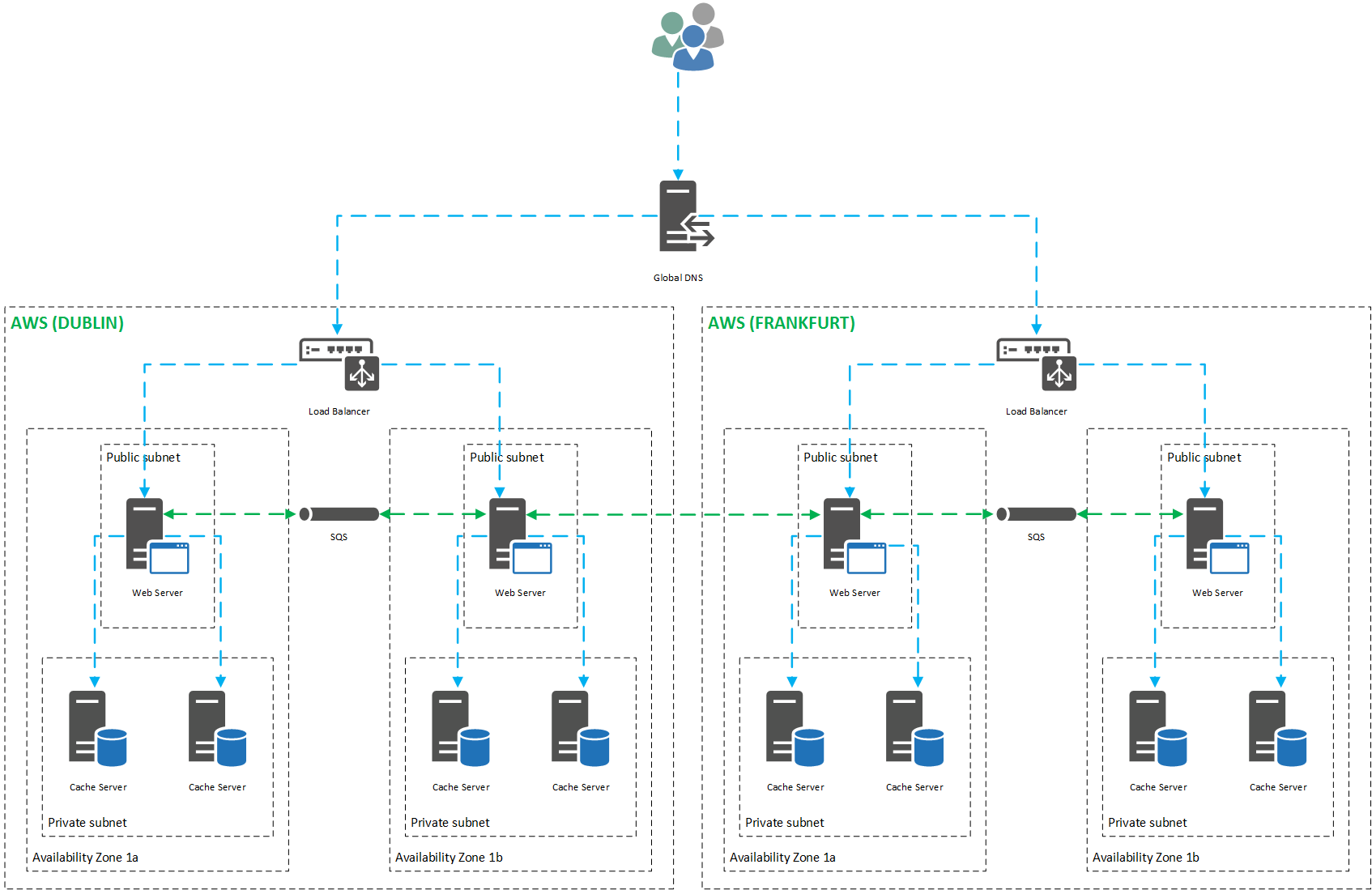
Anatomy of a Microservice
In its simplest form, a Microservice consists of an event-listener and a message-dispatcher. The event-listener polls a service-bus – generally a durable message-queue – and handles incoming messages. Messages consist of instructions bound in metadata and encoded in a data-interchange format such as JSON, or Protobuf.

Anatomy of a Microservice
Daishi.AMQP Key Components

Daishi.AMQP Class Architecture
Connecting to RabbitMQ
Everything starts with an abstraction. The Daishi.AMQP library abstracts all AMQP components, and provides RabbitMQ implementations. First, we need to connect to RabbitMQ. Let’s look at the Connect method in the RabbitMQAdapter class:
public override void Connect() {
var connectionFactory = new ConnectionFactory {
HostName = hostName,
Port = port,
UserName = userName,
Password = password,
RequestedHeartbeat = heartbeat
};
if (!string.IsNullOrEmpty(virtualHost)) connectionFactory.VirtualHost = virtualHost;
_connection = connectionFactory.CreateConnection();
}
A connection is established on application start-up, and is ideally maintained for the duration of the application’s lifetime.
Consuming Messages
A single running instance (generally an *.exe, or daemon) can connect to RabbitMQ and consume messages in a single-threaded, blocking manner. However, this is not the most scalable solution. Processes that read messages from RabbitMQ must subscribe to a Queue, or Exchange. Once subscribed, RabbitMQ manages message delivery, in terms of even-distribution through round-robin, or biased distribution, depending on your Quality of Service (QOS) configuration. Please refer to this post for a more detailed explanation as to how this works.
For now, consider that our Microservice executable can generate multiple processes, each running on a dedicated thread, to consume messages from RabbitMQ in a parallel manner. The AMQPAdapter class contains a method designed to invoke such processes:
public void ConsumeAsync(AMQPConsumer consumer) {
if (!IsConnected) Connect();
var thread = new Thread(o => consumer.Start(this));
thread.Start();
while (!thread.IsAlive)
Thread.Sleep(1);
}
Notice the input variable of type “AMQPConsumer”. Let’s take a look at that class in more detail:
public event EventHandler<MessageReceivedEventArgs> MessageReceived;
public virtual void Start(AMQPAdapter amqpAdapter) {
stopConsuming = false;
}
public void Stop() {
stopConsuming = true;
}
protected void OnMessageReceived(MessageReceivedEventArgs e) {
var handler = MessageReceived;
if (handler != null) handler(this, e);
}
Essentially, the class contains Start and Stop methods, and an event-handler to handle message-delivery. Like most classes in this project, this is an AMQP abstraction. Here is the RabbitMQ implementation:
protected void Start(AMQPAdapter amqpAdapter, bool catchAllExceptions) {
base.Start(amqpAdapter);
try {
var connection = (IConnection) amqpAdapter.GetConnection();
using (var channel = connection.CreateModel()) {
if (createQueue) channel.QueueDeclare(queueName, true, false, false, queueArgs);
channel.BasicQos(0, prefetchCount, false);
var consumer = new QueueingBasicConsumer(channel);
channel.BasicConsume(queueName, noAck, consumer);
while (!stopConsuming) {
try {
BasicDeliverEventArgs;
var messageIsAvailable = consumer.Queue.Dequeue(timeout, out basicDeliverEventArgs);
if (!messageIsAvailable) continue;
var payload = basicDeliverEventArgs.Body;
var message = Encoding.UTF8.GetString(payload);
OnMessageReceived(new MessageReceivedEventArgs {
Message = message,
EventArgs = basicDeliverEventArgs
});
if (implicitAck && !noAck) channel.BasicAck(basicDeliverEventArgs.DeliveryTag, false);
}
catch (Exception exception) {
OnMessageReceived(new MessageReceivedEventArgs {
Exception = new AMQPConsumerProcessingException(exception)
});
if (!catchAllExceptions) Stop();
}
}
}
}
catch (Exception exception) {
OnMessageReceived(new MessageReceivedEventArgs {
Exception = new AMQPConsumerInitialisationException(exception)
});
}
Let’s Start from the Start
Connect to a RabbitMQ instance as follows:
var adapter = RabbitMQAdapter.Instance;
adapter.Init("hostName", 1234, "userName", "password", 50);
adapter.Connect();
Notice the static declaration of the RabbitMQAdapter class. RabbitMQ connections in this library are thread-safe; a single connection will facilitate all requests to RabbitMQ.
RabbitMQ implements the concept of Channels, which are essentially subsets of a physical connection. Once a connection is established, Channels, which are logical segments of the underlying Connection, can be invoked in order to interface with RabbitMQ. A single RabbitMQ connection can support up to 65,535 Channels, although I would personally scale out client instances, rather than establish such a high number of Channels. Let’s look at publishing a message to RabbitMQ:
public override void Publish(string message, string exchangeName, string routingKey,
IBasicProperties messageProperties = null) {
if (!IsConnected) Connect();
using (var channel = _connection.CreateModel()) {
var payload = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchangeName, routingKey,
messageProperties ?? RabbitMQProperties.CreateDefaultProperties(channel), payload);
}
}
Notice the _connection.CreateModel() method call. This establishes a Channel to interface with RabbitMQ. The Channel is encapsulated within a using block; once we’ve completed our operation, the Channel may be disposed. Channels are relatively cheap to create, in terms of resources, and may be created and dropped liberally.
Messages are sent in UTF-8, byte-format. Here is how to publish a message to RabbitMQ:
var message = "Hello, World!";
adapter.Publish(message, "queueName");
This method also contains overloaded exchangeName and routingKey parameters. These are used to control the flow of messages through RabbitMQ resources. This concept is well documented here.
Now let’s attempt to read our message back from RabbitMQ:
string output;
BasicDeliverEventArgs eventArgs;
adapter.TryGetNextMessage("queueName", out output, out eventArgs, 50);
The tryGetNextMessage method reads the next message from the specified Queue, when available. The method will return false in the event that the Queue is empty, after the specified timeout period has elapsed.
Complete code listing below:
private static void Main(string[] args) {
var adapter = RabbitMQAdapter.Instance;
adapter.Init("hostName", 1234, "userName", "password", 50);
adapter.Connect();
var message = "Hello, World!";
adapter.Publish(message, "queueName");
string output;
BasicDeliverEventArgs eventArgs;
adapter.TryGetNextMessage("queueName", out output, out eventArgs, 50);
}
Consistent Message Polling
Reading 1 message at a time may not be the most efficient means of consuming messages. I mentioned the AMQPConsumer class at the beginning of this post. The following code outlines a means to continuously read messages from a RabbitMQ Queue:
var consumer = new RabbitMQConsumerCatchAll("queueName", 10);
adapter.ConsumeAsync(consumer);
Console.ReadLine();
adapter.StopConsumingAsync(consumer);
Note the RabbitMQConsumerCatchAll class instantiation. This class is an implementation of RabbitMQConsumer. All potential exceptions that occur will be handled by this consumer and persisted back to the client along the same Channel as valid messages. As an alternative, the RabbitMQConsumerCatchOne instance can be leveraged instead. Both classes achieve the same purpose, with the exception of their error-handling logic. The RabbitMQConsumerCatchOne class will disconnect from RabbitMQ should an exception occur.
Summary
The Daishi.AMQP library provides a means of easily interfacing with AMQP-driven queuing mechanisms, with built-in support for RabbitMQ, allowing .NET developers to easily integrate solutions with RabbitMQ. Click here for Part 1 in a tutorial series outlining the means to leverage Daishi.AMQP in your .NET application.
Connect with me: