Balancing demand and processing power
Autoscaling Microservices
In the previous tutorial, we demonstrated the throughput increase by invoking multiple instances of SimpleMathMicroservice, in order to facilitate a greater number of concurrent inbound HTTP requests. We experimented with various configurations, increasing the count of simultaneously running instances of SimpleMathMicroservice until the law of diminishing returns set it.
This is a perfectly adequate configuration for applications that absorb a consistent number of inbound HTTP requests over any given extended period of time. Most web applications, of course, do not adhere to this model. Instead, traffic tends to fluctuate, depending on several factors, not least of which is the type of business that the web application facilitates.
This presents a significant problem, in that we cannot manually throttle the number of concurrently running Microservice instances on-demand, as traffic dictates. We need an automated mechanism to scale our Microservice instances adequately.
Autoscaling involves more than simply increasing the count of running instances during heavy load. It also involves the graceful termination of superfluous instances, or instances that are no longer necessary to meet the demands of the application as load is reduced. Daishi.AMQP provides just such features, which we’ll cover in detail.
QueueWatch
QueueWatch is a mechanism that allows the monitoring of RabbitMQ Queues in real time. It achieves this by polling the RabbitMQ Management API (mentioned in Part #3) at regular intervals, returning metadata that describes the current state of each Queue.
Metadata
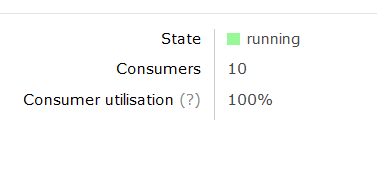
RabbitMQ exposes important metadata pertaining to each Queue. This metadata is presented in a user-friendly manner in the RabbitMQ Management Console:

Message Rates
These metrics represent the rates at which messages are processed by RabbitMQ. “Publish” illustrates the rate at which messages are introduced to the server, while “Deliver” represents the rate at which messages are dispatched to listening consumers (Microservices, in our case).
This information is readily available in the RabbitMQ Management API. QueueWatch effectively harvests this information, comparing the values retrieved in the latest poll with those retrieved in the previous, to monitor the flow of messages through RabbitMQ. QueueWatch can determine whether or not any given Queue is idling, overworked, or somewhere in between.
Once a Queue is determined to be under heavy load, QueueWatch triggers an event, and dispatches an AutoScale message to the Microservice consuming the heavily-laden Queue. The Microservice can then instantiate more AMQPConsumer instances in order to drain the Queue sufficiently.
Just Show Me the Code
Create a new Microservice instance called QueueWatchMicroservice; an implementation of Microservice, and add the following code to the Init method:
var amqpQueueMetricsManager = new RabbitMQQueueMetricsManager(false, "localhost", 15672, "paul", "password");
AMQPQueueMetricsAnalyser amqpQueueMetricsAnalyser = new RabbitMQQueueMetricsAnalyser(
new ConsumerUtilisationTooLowAMQPQueueMetricAnalyser(
new ConsumptionRateIncreasedAMQPQueueMetricAnalyser(
new DispatchRateDecreasedAMQPQueueMetricAnalyser(
new QueueLengthIncreasedAMQPQueueMetricAnalyser(
new ConsumptionRateDecreasedAMQPQueueMetricAnalyser(
new StableAMQPQueueMetricAnalyser()))))), 20);
AMQPConsumerNotifier amqpConsumerNotifier = new RabbitMQConsumerNotifier(RabbitMQAdapter.Instance, "monitor");
RabbitMQAdapter.Instance.Init("localhost", 5672, "paul", "password", 50);
_queueWatch = new QueueWatch(amqpQueueMetricsManager, amqpQueueMetricsAnalyser, amqpConsumerNotifier, 5000);
_queueWatch.AMQPQueueMetricsAnalysed += QueueWatchOnAMQPQueueMetricsAnalysed;
_queueWatch.StartAsync();
There’s a lot to talk about here. Firstly, remember that the primary function of QueueWatch is to poll the RabbitMQ Management API. In doing so, QueueWatch returns several metrics pertaining to each Queue. We need to decide which metrics we are interested in.
Metrics are represented by implementations of AMQPQueueMetricAnalyser, and chained together as per the Chain of Responsibility Design Pattern. Each link in the chain is executed until a predefined performance condition is met. For example, let’s consider the ConsumerUtilisationTooLowAMQPQueueMetricAnalyser. This implementation of AMQPQueueMetricAnalyser inspects the ConsumerUtilisation metric, and determines whether the value is less than 99%, in which case, there are not enough consuming Microservices to adequately drain the Queue. At this point, a ConsumerUtilisationTooLow value is returned, the chain of execution ends, and QueueWatch issues an AutoScale directive:
public override void Analyse(AMQPQueueMetric current, AMQPQueueMetric previous, ConcurrentBag<AMQPQueueMetric> busyQueues, ConcurrentBag<AMQPQueueMetric> quietQueues, int percentageDifference) {
if (current.ConsumerUtilisation >= 0 && current.ConsumerUtilisation < 99) {
current.AMQPQueueMetricAnalysisResult = AMQPQueueMetricAnalysisResult.ConsumerUtilisationTooLow;
busyQueues.Add(current);
}
else analyser.Analyse(current, previous, busyQueues, quietQueues, percentageDifference);
}
Scale-Out Directive

Scaling out
QueueWatch must issue Scale-Out directives through dedicated Queues in order to adhere to the Decoupled Middleware design. QueueWatch should not know anything about the downstream Microservices, and should instead communicate through AMQP, specifically, through a dedicated Exchange.
Each Microservice must now listen to 2 Queues. E.g., SimpleMathMicroservice will continue listening to the Math Queue, as well as a Queue called AutoScale, for the purpose of demonstration. SimpleMathMicroservice will receive Scale-Out directives through this Queue. We should modify SimpleMathMicroservice accordingly:
public void Init() {
_adapter = RabbitMQAdapter.Instance;
_adapter.Init("localhost", 5672, "guest", "guest", 50);
_rabbitMQConsumerCatchAll = new RabbitMQConsumerCatchAll("Math", 10);
_rabbitMQConsumerCatchAll.MessageReceived += OnMessageReceived;
_autoScaleConsumerCatchAll = new RabbitMQConsumerCatchAll("AutoScale", 10);
_autoScaleConsumerCatchAll.MessageReceived += _autoScaleConsumerCatchAll_MessageReceived;
_consumers.Add(_rabbitMQConsumerCatchAll);
_adapter.Connect();
_adapter.ConsumeAsync(_autoScaleConsumerCatchAll);
_adapter.ConsumeAsync(_rabbitMQConsumerCatchAll);
}
Create a Topic Exchange called “monitor”. QueueWatch will publish to this Exchange, which will route the message to an appropriate Queue. Now create a binding between the monitor Exchange and the AutoScale Queue:
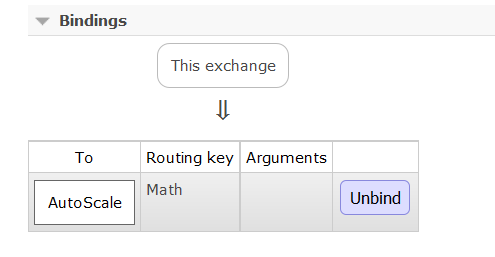
Exchange Binding
Note that the Routing Key is the name of the Queue under monitor. If QueueWatch determines that the Math Queue is under load, then it will issue a Scale-Out directive to the monitor Exchange, with a Routing Key of “Math”. The monitor Exchange will react by routing the Scale-Out directive to the AutoScale Queue, to which an explicit binding exists. SimpleMathMicroservice consumes the Scale-Out directive and reacts appropriately, by instantiating a new AMQPConsumer:
if (e.Message.Contains("scale-out")) {
var consumer = new RabbitMQConsumerCatchAll("Math", 10);
_adapter.ConsumeAsync(consumer);
_consumers.Add(consumer);
}
else {
if (_consumers.Count <= 1) return;
var lastConsumer = _consumers[_consumers.Count - 1];
_adapter.StopConsumingAsync(lastConsumer);
_consumers.RemoveAt(_consumers.Count - 1);
}
Summary
QueueWatch provides a means of returning key RabbitMQ Queue metrics at regular intervals, in order to determine whether demand, in terms of the number of running Microservice instances, is waxing or waning. QueueWatch also provides a means of reacting to such events, by publishing AutoScale notifications to downstream Microservices, so that they can scale accordingly, providing sufficient processing power at any given instant. The process is simplified as follows:
- QueueWatch returns metrics describing each Queue
- Queue metrics are compared against the last batch returned by QueueWatch
- AutoScale messages are dispatched to a Monitor Exchange
- AutoScale messages are routed to the appropriate Queue
- AutoScale messages are consumed by the intended Microservices
- Microservices scale appropriately, based on the AutoScale message
Next Steps
- Prevent a “bounce” effect as traffic arbitrarily fluctuates for reasons not pertaining to application usage, such as network slow-down, or hardware failure
- The current implementation compares metrics in a very simple fashion. Future implementations will instead graph metric metadata, and react to more thoroughly defined thresholds
Connect with me: