Overview
Caching strategies have become an integral component in today’s software applications. Distributed computing has resulted in caching strategies that have grown quite complex. Coupled with Cloud computing, caching has become something of a dark art. Let’s walk through the rationale behind a cache, the mechanisms that drive it, and how to achieve a highly available, durable cache, without persisting to disk.
Why We Need a Cache
Providing fast data-access
Data stores are growing larger and more distributed. Caches provide fast read capability and enhanced performance vs. reading from disk. Data distributed across multiple hardware stacks, across multiple geographic locations can be centralised at locations geographically close to application users.
Absorbing traffic surges
Sudden bursts in traffic can cause contention in terms of data-persistence. Storing data in memory removes the overhead involved in disk I/O operations, easing the burden on network resources and application threads.
Augmenting NoSQL
NoSQL has gained traction to the extent that it is now pervasive. Many NoSQL offerings, such as Couchbase, implement an eventual-consistency model; essentially, data will eventually persist to disk at some point after a write operation is invoked. This is an effective big data management strategy, however, it results in potential pitfalls on the consuming application-side. Consider an operation originating from an application that expects data to be written immediately. The application may not have the luxury of waiting until the data eventually persists. Caching the data ensures almost immediate availability.
Another common design in NoSQL technology is to direct both reads and writes, that are associated with the same data segment, to the node on which the data segment resides. This minimises node-hopping and ensures efficient data-flow. Caching can further augment this process by reducing the NoSQL data-store’s requirement to manage traffic by providing a layer of cached metadata before the data-store, minimising resource-consumption. The following design illustrates the basic structure of a managed cache in a hosted environment using Aerospike – a flash optimised, in-memory database:

Distributed Cache
High Availability and the Cloud
High availability is a principal applied to hosted solutions, ensuring that the system will be online, if even partly, regardless of failure. Failure takes into account not just hardware or software failure, such as disk failure, or out-of-memory exceptions, but also controlled failure, such as machine maintenance.
How Super Data Centers Manage Infrastructure
Data Centers, such as those managed by Amazon Web Services and Microsoft Azure, distribute infrastructure across regions – physical locations separated geographically. Infrastructure contained within each region is further segmented into Availability Zones, or Availability Sets. These are physical groupings of hosted services within hardware stacks – e.g., server racks. Hardware is routinely patched, maintained, and upgraded within Data Centers. This is applied in a controlled manner, such that resources contained within Availability Zone/Set X will not be taken offline at the same time as resources contained within Availability Zone/Set Z.
Durability and the Cloud
To achieve high availability in hosted applications, the applications should be distributed across Availability Zones/Sets, at least. To further enhance the degree of availability, applications can be distributed across separate regions. Consider the following design:
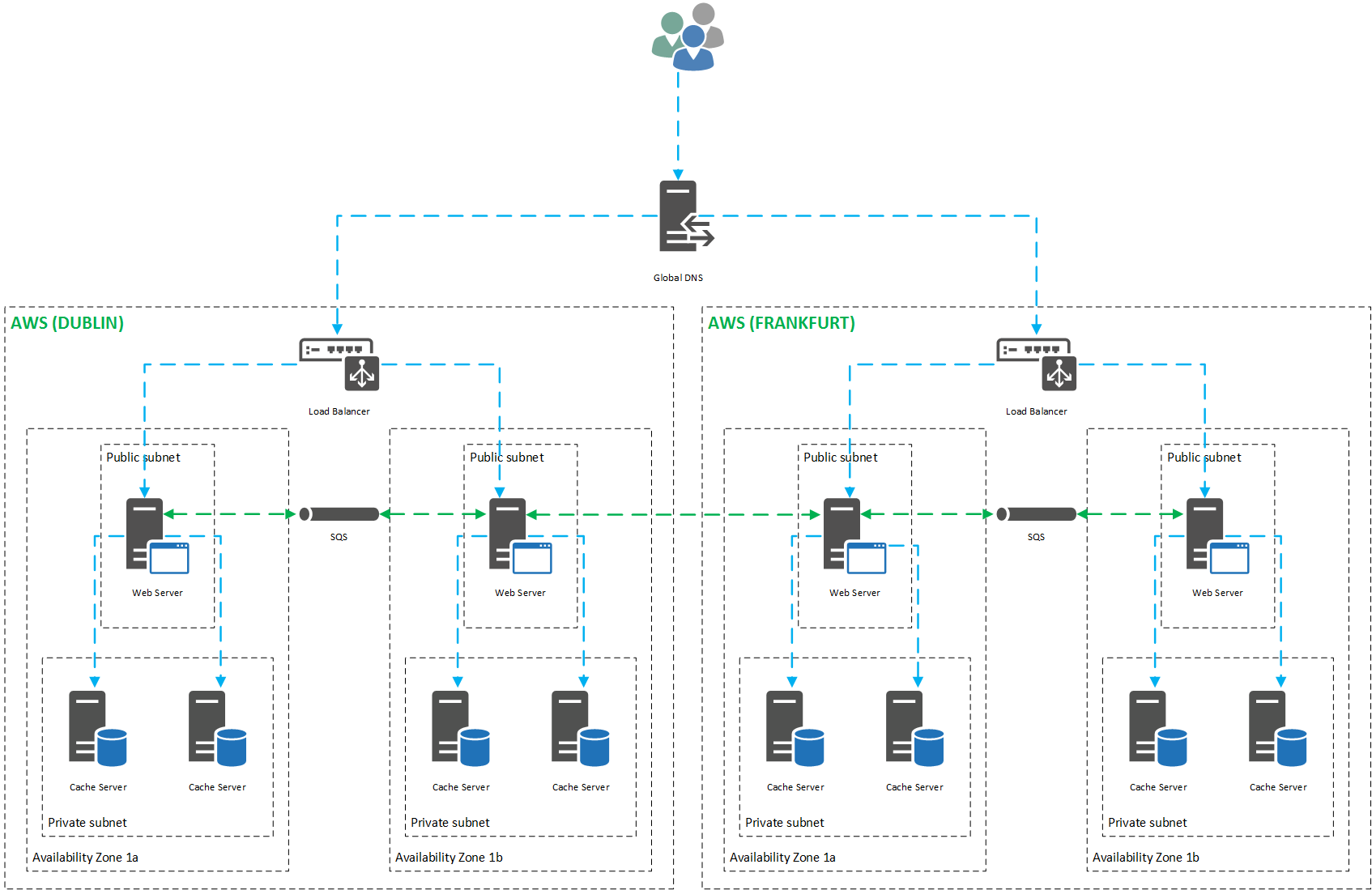
Highly available, durable, cloud-based cache
When Things Fall Over
Notice that the design provides 8 Cache servers, distributed evenly across both region and availability zone. Thus, should any given Availability Zone fail, 3 Availability Zones will remain online. In the unlikely event that a Data Center fails, and all Availability Zones fail, the second region will remain online – our application can be said to be highly available.
Note that the design includes AWS Simple Queue Service (SQS) to achieve Cross Data Center Data Replication (XDR). The actual implementation, which I will address in an upcoming post, is slightly more complex, and is simplified here for clarity. Enterprise solutions, such as Aerospike and Couchbase offer XDR as a function.
Traffic is load balanced evenly (or in a more suitable manner) across Availability Zones. A Global DNS service, such as AWS Route 53, directs traffic to each region. In situations where all regions and Availability Zones are available, we might consider distributing traffic based on geographic location. Users based in Ireland can be routed to AWS-Dublin, while German users might be routed to AWS-Frankfurt, for example. Route 53 can be configured to distribute all traffic to live regions, should any given region fail entirely.
Taking Things a Step Further by Minimising PCI DSS Exposure
Applications that handle financial data, such as Merchants, must comply with the requirements outlined by the PCI Data Security Standard. These requirements apply based on your application configuration. For example, storing payment card details on disk requires a higher level of adherence to PCI DSS than offloading the storage effort to a 3rd party.
Requirements for Handling Financial Data
The PCI DSS define data as 2 logical entities; data-in-transit and data-at-rest. Data-at-rest is essentially data that has been persisted to a data-store. Data-in-transit applies to data stored in RAM, although the requirements do not specify that this data must be transient – that it must have a point of origin and a destination. Therefore, storing data in RAM would, at least from a legal-perspective, result in a reduced level of PCI DSS exposure, in that requirements pertaining to storing data on disk, such as encryption, do not apply.
Of course, this raises the question; should sensitive data always be persisted to hard-storage? Or, is storing data in a highly available and durable cache sufficient? I suspect at this point that you might feel compelled to post a strongly-worded comment outlining that this idea is ludicrous – but is it really? Can an in-memory cache, once distributed and durable enough to withstand multiple degrees of failure, operate with the same degree of reliability as a hard data-store? I’d certainly like to prove the concept.
Summary
Caching data allows for increased throughput and optimised application performance. Enhancing this concept further, by distributing your cache across physical machine-boundaries, and further still across multiple geographical locations, results in a highly available, durable in-memory storage mechanism.
Hosting cache servers within close proximity to your customers allows for reduced latency and an enhanced user-experience, as well as providing for several degrees of failure; from component, to software, to Availability Zone/Set, to entire region failure.
Connect with me:
